
В уроке 25 мы познакомились со структурами, для чего они нужны, и поняли, что без них жизнь программы (до её компиляции) была бы очень разрозненной и хаотичной. Поэтому в последующих уроках мы постоянно используем структуры, также используем указатели на них в качестве параметров для функций, а также докатились и до того, что уже начали использовать указатели на функции в структурах.
Теперь самое время залезть немного поглубже в наши структуры. Как именно там хранятся данные, не тратится ли лишнего места, а если тратится, то не во благо ли это, наоборот, нам будет, нельзя ли как-то этим распределением данных в памяти, отведённой под структуры, управлять, перевернуть их как-то с ног на голову. Чтобы это узнать, мы не будем пока ничего рисовать побайтно, побитно, не будет у нас сегодня никакой теоретической части по первому пункту урока, иначе в нашем проекте теряется интрига.
Поэтому давайте сразу приступим к проекту, который мы сделаем, как всегда, из проекта прошлого урока с именем MYPROG30 и присвоим ему имя MYPROG31.
Откроем наш проект в Eclipse, произведём его первоначальную настройку и удалим весь наш код из функции main() за исключением возврата. Функция main() приобретёт вот такой вид
int main()
{
return 0; //Return an integer from a function
}
Первым делом давайте объявим глобальную структуру и присвоим ей псевдоним типа
|
1 2 3 4 5 6 7 8 9 |
float yf, zf; //---------------------------------------------- typedef struct { unsigned char x; unsigned short y; unsigned int z; } my_arg_t; //---------------------------------------------- |
В функции main() выедем размер памяти в байтах, занимаемой нашей структурой
|
1 2 3 |
int main() { printf("sizeof data is %d\n", sizeof(my_arg_t)); |
Посмотрим результат
![]()
Давайте посчитаем. У нас в структуре одна переменная 1-байтовая, одна 2-байтовая и одна 4-байтовая. Должно получиться 7, а у нас 8. Странно, не правда ли?
Давайте тогда создадим переменную типа нашей структуры, присвоим какие-нибудь узнаваемые в дальнейшем в дампе памяти числа её полям и выведем результат в консоль
|
1 2 3 4 5 6 7 8 |
printf("sizeof data is %d\n", sizeof(my_arg_t)); my_arg_t my_arg; my_arg.z = 0x11223344; printf("z = 0x%08X\n", my_arg.z); my_arg.y = 0x5566; printf("y = 0x%04X\n", my_arg.y); my_arg.x = 0x77; printf("x = 0x%02X\n", my_arg.x); |
Почему я наоборот, начал с z, а закончил x, вы поймёте позже, когда будем работать с объединениями.
Соберём код, посмотрим результат в консоли
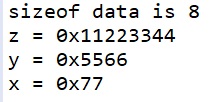
Всё хорошо присвоилось.
Поставим точку останова на последней строке данного кода, выполним в отладчике до неё код и посмотрим в дизассемблере, что у нас там получилось. Я покажу здесь лишь строчки занесения в стек значений наших полей

Если начать снизу, то начало памяти под структуру у нас находится по адресу esp+0x18, следующее поле находится не в следующем байте, а сразу в esp+0x1A, то есть не в следующем байте, а через 2 байта, третье поле, как положено отстаёт от 2-байтового второго поля на 2 байта и находится по адресу 0x1C.
Что же произошло? И что находится по адресу 0x19?
Получается, что данный адрес у нас выпал и никак не используется.
А произошло выравнивание полей структуры. Процессору легче обращаться по адресам, кратным четырём, ну в крайнем случае двум. Поэтому и выравнивание. Засчёт этого мы теряем байт памяти, соответственно, в век огромных вычислительных ресурсов это не так страшно, но зато код будет работать лучше.
Теперь давайте посмотрим, как именно распределяются байты многобайтовых чисел в памяти (хотя мы и так уже знаем, что от старшего к младшему, но тем не менее давайте уточним).
Узнаем адрес стека
![]()
Посмотрим теперь наш стек в мониторе памяти

Я выделил наши поля в памяти, мы видим, что один байт памяти, отведённой под переменную структуры, у нас не участвует в процессе и. скорее всего там осталось то значение, которое там и было до работы кода.
В принципе, можно обойтись и без отладки (но с отладкой конечно же удобно, но порой есть ситуации когда отладка вообще не доступна). Мы же можем получить адреса наших полей и вывести их в консоль. Давайте это и сделаем
|
1 2 3 4 |
printf("x = 0x%02X\n", my_arg.x); printf("addr x = 0x%08X\n", (unsigned int)&my_arg.x); printf("addr y = 0x%08X\n", (unsigned int)&my_arg.y); printf("addr z = 0x%08X\n", (unsigned int)&my_arg.z); |
А вот и результат
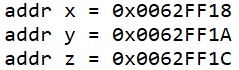
Отлично!
Чтобы убедиться ещё в выравнивании, давайте в объявлении структуры закомментируем 2-байтовое поле
typedef struct
{
unsigned char x;
// unsigned short y;
Соответственно, вот эти строчки в main() мы тоже закомментируем
// my_arg.y = 0x5566;
// printf("y = 0x%04X\n", my_arg.y);
...
// printf("addr y = 0x%08X\n", (unsigned int)&my_arg.y);
Соберём код и посмотрим результат

У нас также отводится под структуру место в памяти в размере 8 байт, хотя мы ещё одну двухбайтовую переменную убрали, должно же быть вообще 5, вот такое выравнивание. И адрес поля z отстаёт от адреса поля x на целых 4 байта.
Оказывается, процессом выравнивания мы можем в нашей программе управлять, а также можем управлять и процессом расположения байтов в памяти.
Для чего нужно управлять выравниванием, ведь выравнивание — это же путь к оптимизации кода.
А для того, что не всегда слишком много памяти. Представим ситуацию, что мы пишем код для контроллера, в котором памяти не так много. Вот в этом случае это бывает полезно. Также полезно знать команды управления некоторыми процессами при чтении чужих кодов, так как они вполне там могут использоваться, а мы не будем при их чтении знать, что это такое.
Делается это посредством использование директивы #pragma, которая позволяет нам давать некоторые инструкции компилятору. Например инструкция pack после ключевого слова pragma как раз и управляет выравниванием байтов.
Добавим такую директиву перед объявлением нашей структуры
|
1 2 |
#pragma pack(push, 1) typedef struct |
В данном случае в скобках указывается ключевое слово push, которое укладывает в стек компилятора количество байтов, на которое нужно будет выравнивать поля. Получается, что если мы положим 1 в стек компилятора, то выравнивания вообще не будет, так как 1 байт — это минимальная единица информации для выравнивания.
После этого в полях структуры никакого выравнивания происходить не будет. Также не забываем в конце объявления структуры данное значение из стека компилятора выбрать, чтобы вернуть для дальнейших объявлений выравнивание по умолчанию
|
1 2 |
} my_arg_t; #pragma pack(pop) |
Соберём наш код и получим теперь следующий результат

Ну вот, теперь ничего не экономится, посмотрим также это в отладчике в дампе памяти

Давайте также везде раскомментируем наш 2-байтовый y — и его объявление в структуре и его использование в main().
После этого мы получим следующий результат
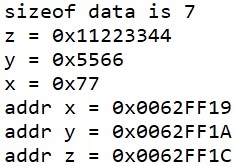
А это в памяти

А, забыл самое главное сказать. Мы в команде push во втором параметре применяли единицу для выравнивания. Допустимы значения 1, 2, 4, 8 и 16. То есть мы можем назначить выравнивание максимум на 16 байтов. Это скорее всего бывает полезно в использовании символьных массивов в структурах. Я пробовал установить перед объявлением структуры максимальное выравнивание, а также выравнивание на 8 байтов, но эффекта не получил, выравнивалось всё к четырём, видимо, написание кода под именно 32-разрядный процессор даёт своё. Также мы понимаем, что если мы опять уберём поле y и установим выравнивание в 2 байта, то получим размер структуры в памяти в 6 байт. Я это пробовал, можете тоже попробовать.
Теперь порядок следования байтов в памяти в многобайтовых числах.
Оказывается, мы его тоже можем поменять, думаю, что это полезно будет не только при чтении чужого кода, но и при работе со специфическими устройствами, подключенными к компьютеру, а также при работе с некоторыми сетевыми протоколами, в которых следование байтов в передаваемых числах идёт наоборот — от старшего к младшему. Кстати такой порядок называется big endian, а от младшего к старшему — little endian. Значит, получается, что для того, чтобы перевернуть порядок следования байтов, то мы должны включить порядок big endian. Для этого существует своя pragma.
Чтобы нам пока не путаться в директивах, предыдущие две мы пока закомментируем
//#pragma pack(push, 1)
...
//#pragma pack(pop)
Добавим следующую директиву перед объявлением нашей структуры
|
1 2 |
#pragma scalar_storage_order big-endian typedef struct |
По окончанию объявления, соответственно, вернём всё на место
|
1 2 |
} my_arg_t; #pragma scalar_storage_order little-endian |
Тем самым мы объявили обратный порядок следования байт, а по окончанию вернули всё на место.
Если мы попытаемся собрать сейчас код, то получим вот такую ошибку

Мы теперь не можем получить адреса полей структуры. В принципе, зная теперь механизм выравнивания, мы их можем вычислить по адресу переменной структуры, но нам в принципе это и не надо, нам надо посмотреть, как расположились байты в памяти, поэтому таким же образом посмотрим их в дампе стека, конечно же сначала закомментировав строчки кода вывода адресов полей в консоль

Как мы изволим видеть, байты в полях y и z теперь следуют от старшего к младшему, в порядке big endian.
Закомментируем наши директивы, а также вообще объявление всей структуры.
Теперь давайте приступим к пункту 2 нашего урока и проведём краткое знакомство с объединениями.
Почему краткое, а потому что они сейчас почти нигде не используются.
Хотя объединения сейчас встречаются уже редко, но вдруг кому-то попадутся при разборе чужих кодов (а это лучше чем любая книга), чтобы он не гадал потом, что это такое.
Объединение — это почти такая же структура, только память в объединении под поля распределяется по другому. Память выделяется на всё объединение только в количестве одного поля, имеющего самый большой размер. То есть если у нас самое большое поле будет иметь размер 4 байта, а различных полей будет сколько угодно, то память под всё объединение выделится только 4 байта. Поэтому значение полей актуально не всё время жизни переменной типа объединения, а до тех пор, пока мы не запишем какие-нибудь данные в другое поле и они спокойно перезапишут либо всё поле, либо его часть.
Объявляется объединение таким же образом как и структура, только вместо ключевого слова struct используется ключевое слово union
Объединения придуманы были давно, когда не было столько много памяти и её количество, выделяемое программе, желательно чтобы было как можно меньшим. Сейчас повсеместно используются структуры. Разве что, если писать программу под контроллер AtTiny, в котором памяти кот наплакал, нам могут объединения пригодиться. И также было целесообразно использовать объединения только в том случае, когда нам не приходилось долго пользоваться значениями полей, только на какое-то время.
Тем не менее в нашем проекте мы с объединениями сейчас познакомимся и испытаем их на деле.
Объявим глобальное объединение и присвоим его типу псевдоним
|
1 2 3 4 5 6 7 |
//#pragma pack(pop) typedef union { unsigned char x; unsigned short y; unsigned int z; } my_arg_t; |
Мы создали точь в точь такие же поля, как и в нашей предыдущей структуре, поэтому код в функции main() нам вообще пока менять не надо. Просто запустим наш код на выполнение, раскомментировав перед этим строки вывода адресов полей в консоль

Ну как? Круто? Размер на всё объединение 4 байта, все переменные читаются (правда до поры — до времени) и адрес у них у всех один и тот же.
Давайте поставим точку останова до присвоения полям значений, куда-то вот сюда
Запустим наш код на выполнение в отладчики до этой строки и поглядим, что у нас творится в стеке

Пока там какие-то случайные неизвестные нам значения.
Выполним один шаг программы (присвоение значения полю z) посмотрим, что там теперь
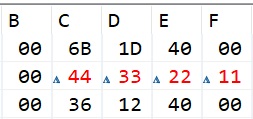
Число z туда уложилось, как положено в правильном порядке следования байтов, хотя теперь мы знаем, что этот порядок мы можем изменить легко.
Выполним ещё 2 шага, чтобы у нас записалось в память следующее число — y и посмотрим результат
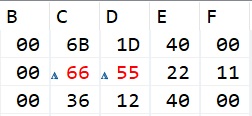
Мы видим, что два младших байта числа z у нас перезаписались значением y. Если мы сейчас захотим воспользоваться полем z нашего объединения, то мы получим искажённый результат. Мы это позже проверим. Теперь выполним ещё два шага для того, чтобы в память прописалось 1-байтовое число x и также посмотрим результат
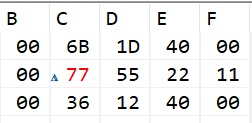
Мы видим, что самый младший байт обоих наших чисел y и z опять затёрся, то есть мы можем теперь пользоваться только числом x.
Выведем теперь наши испорченные результаты в консоль.
Сначала после вывода значения поля y выведем ещё раз значение поля z, чтобы посмотреть, как оно испортится
|
1 2 |
printf("y = 0x%04X\n", my_arg.y); printf("z = 0x%08X\n", my_arg.z); |
Затем после вывода поля x выведем заново значения полей y и z,чтобы увидеть как они испортятся оба.
|
1 2 3 |
printf("x = 0x%02X\n", my_arg.x); printf("y = 0x%04X\n", my_arg.y); printf("z = 0x%08X\n", my_arg.z); |
Соберём код и посмотрим результат в консоли

Результат не нуждается ни в каком объяснении. Сначала испортился z, а потом z испортился ещё раз, а ещё испортился младший байт y.
Давайте присвоим другое число нашему самому большому числу z и посмотрим. как после этого изменятся значения x и y
|
1 2 3 4 5 |
printf("z = 0x%08X\n", my_arg.z); my_arg.z = 0xAABBCCDD; printf("x = 0x%02X\n", my_arg.x); printf("y = 0x%04X\n", my_arg.y); printf("z = 0x%08X\n", my_arg.z); |
Посмотрим результат
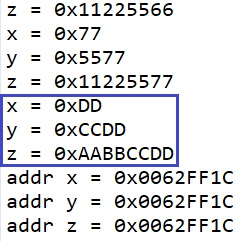
Вот так. Наши x и y в этом случае полностью затёрлись.
Поэтому я считаю, что объединением надо пользоваться только в крайнем случае, когда нам дорог каждый байт памяти и пользоваться им нужно очень аккуратно. Теперь, зная, в каком случае и что затирается, если мы даже и воспользуемся объединением, то воспользуемся им грамотно. Также можно, в принципе, придумать использование объединений для удобной замены младших байтов чисел в каких-то специфических случаях.
Итак, на данном уроке мы узнали, каким образом выравниваются данные в структурах, также научились данным выравниванием управлять, также научились управлять порядком следования байтов в многобайтовых числах и познакомились с объединениями, с их смыслом в программировании и каким образом ими пользоваться.
Всем спасибо за внимание!
Предыдущий урок Программирование на C Следующий урок
Смотреть ВИДЕОУРОК (нажмите на картинку)

Для Linux дебаг выглядит иначе. Но тоже интересно
0x0000000000401142 : movl $0x11223344,-0x4(%rbp)
0x0000000000401149 : movw $0x5566,-0x6(%rbp)
0x000000000040114f : movb $0x77,-0x8(%rbp)
и в стеке данные лежат показательно, с 00 в «месте выравнивания»
(gdb) x/10x $rsp
0x7fffffffe000: 0xffffe100 0x00007fff 0x55660077 0x11223344
0x7fffffffe010: 0x00000000 0x00000000 0xf7e0ab75 0x00007fff
0x7fffffffe020: 0xffffe108 0x00007fff